Table of Contents
Introduction
After more than three years of using Neo4J (a graph database based on the JVM), I wanted to share the benefits and drawbacks of using such a technology.
What is a Graph Database ?
First things first, a graph database is a NoSQL database based (as its name suggests) on the graph’s theory. It was created to address the limitations of relational databases by storing complex interconnected data, in a pure conceptual way using nodes and relationships.
The first concepts of network / graph models for storing and reading data were imagined in the late 1960s but commercial versions only started to appear in the early 2000s. At this point they were mostly used for research and web pages indexation because they weren’t stable and secure enough. Then in the late 2000s, ACID (a paradigm used to guarantee data integrity) compliant graph databases such as Neo4J became available.
Nowadays, they’re mainly used in social networks, AIs, banking, tracking and research.
Graph Data Model
The Graph Data Model is composed of the following components:
- Nodes : These are the main entities of a graph, they’re composed of properties and labels.
- Properties : key/value pairs stored within entities.
- Labels : Attribute / type used to group similar nodes together.
- Relationships : The connections between nodes, they’re composed of a type/name and can hold properties as well.
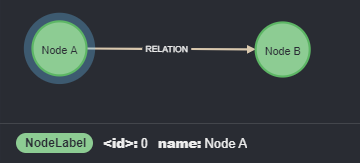
In the above example, we have two nodes (Node A and Node B) having the same NodeLabel and a name property, connected by a relationship having the RELATION type.
If we compare the graph data model to the relational one, you can think of Nodes as rows, Properties as columns, labels as tables (or a group_id column) and Relationships as foreign keys or join tables, if they hold properties.
You need to know that every relational database model is transposable to a graph model. It’s also possible to do it the other way (graph to relational) but you’re less likely to do it because of the limitations of relational databases, that we will discuss in the next part.
Relational vs. Graph Databases
Now that you have a bit of an idea about what a graph database is, let’s talk about the main differences with a relational database.
Retrieving connected data
In relational databases, “connection” to other entities/rows is done by referring primary keys and foreign key columns, using joins.
Joins are processed at query time matching primary and foreign keys of all rows of the related tables (loops iterating on every row of every joined tables).
These operations are really heavy and even if indexes can be used to optimize it, adding rows in an exponential way will tend to degrade performances in an exponential way.
Note that: The following example is comparing a single RDBMS instance over a single graph database instance, companies are scaling-up (adding more “shared” instances of RDBMSes) to dilute their limitations.
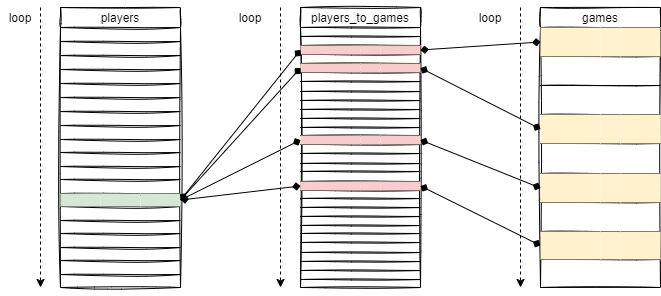
In the above relational example, we used the following query to find a player’s games list:
SELECT g.id, g.name FROM players p
INNER JOIN players_to_games ptg ON p.id = ptg.player_id
INNER JOIN games g ON ptg.game_id = g.id
WHERE p.id = ?
At first, the database engine iterates over the players rows to find one having id = ?.
Then it iterates over players_to_games (potentially millions of rows) to locate all the rows referencing our player ID and iterates again on games (potentially other millions of rows) to locate all rows referencing previous game_id.
Now that it has made millions + millions + millions iterations, it finally returns the 4 games in the player’s list.
I’m exaggerating it, so you can understand the difference, in fact, indexes are optimizing it a lot. But even with indexes, your RDBMS is iterating over unneeded data.
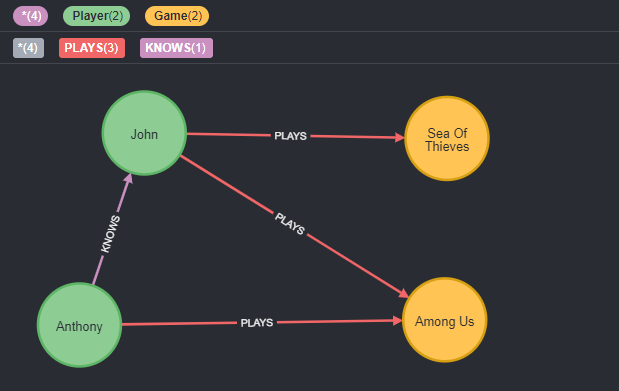
In the above graph version, if we use the following Cypher query to retrieve our player’s games list:
MATCH (p:Player)-[:PLAYS]->(g:Game)
WHERE id(p) = ?
RETURN g
Because of the way data is stored in a graph, our
Playernode is literally connected to other nodes by its relationships edges.
At first, the database also iterates over all the Player nodes (potentially millions of nodes) to find the one having id = ?.
Then it follows/iterates over direct relationships having the PLAYS type and directly returns their targets, our so called Game nodes.
We could also imagine having millions and millions of relations to iterate over, but the difference with relational DBs is that since they’re connected to our Player, 100% of these relations are related to it, the engine would never end iterating on unneeded/unrelated data.
Data constraints and schemas
In a relational database, you must respect some standards.
Each table must have a primary key (if it doesn’t, most engines create a hidden one). Every row have (and must have) the same number of columns and the same column order.
A schema holds your tables, columns and constraints configuration so that when you insert/update data, the engine can verify that every row-column values meet the requirements.
There’s no schema in a graph database.
Well… you can set up some indexes and constraints on properties (like unicity and existence) and there’s also graph databases allowing the use of pseudo schema-like features (like ArangoDB), but graphs aren’t meant to have one.
Each graph element has (depending on the graph databases) an internal auto-incremented and read-only id field.
Each node and each relationship having the same labels / types can have different (and a different amount of) properties.
Pros and cons
Despite the fact graph databases outrun relational ones in many ways, they at the moment cannot fully replace them in many cases.
The graph databases are faster at retrieving data because they only process the concrete number of relationships a node has and having schema-less data is also a good advantage when it comes to model changes and evolutions.
These databases are also younger and less mature than relational databases. They for now have some issues at handling a large amount of transactions and, for most databases only supports master to slave replication.
| Pros | Cons |
|---|---|
| Faster at retrieving complex interconnected data | Less Mature (lacking some scaling/clustering features for now) |
| Flexible and agile structure with a schema-less design |
When (not) to use a graph database
The strength of a database can be measured by comparing: data integrity, performances, efficiency and scalability.
The main purpose of a graph database can be roughly summarized to make quicker and simpler query results. They get particularly useful and efficient on models where relational databases reach their capacity limits, because they’re less influenced by data quantity and complexity.
However, graph databases aren’t a perfect solution for every problem. Far from it. Here are some simple questions to help you choose between graph and relational:
- Does my data structure change really often ?
- Graph / Schema-less is a good choice
- Is my data highly interconnected ?
- Graph is a good choice
- Is retrieving data more important than storing it ?
- Graph is a good choice
- Does an entity need to store large chunks of information ?
- Relational is a good choice
- Do I need to handle a large amount of requests in real-time ?
- Relational is a good choice
Note that: You can also make benefits of using both of these technologies, like some famous social networks, using relational databases as persistent master data and graph databases as a cache / fast resolution engine, referencing IDs of relational entities.